highlight: vs2015
为什么要用diff算法
当页面上的数据发生变化时,Vue 不会立即渲染。而是经过 diff 算法,判断出哪些是不需要变化的,哪些是需要变化更新的,只需要更新那些需要更新的 DOM 就可以了,这样就减少了很多不必要的 DOM 操作,大大提升了性能。
diff算法就是进行虚拟节点对比,并返回一个patch对象,用来存储两个节点不同的地方,最后用patch记录的消息去局部更新Dom。
diff算法原理
diff 的核心就是同层节点进行比较,深度优先
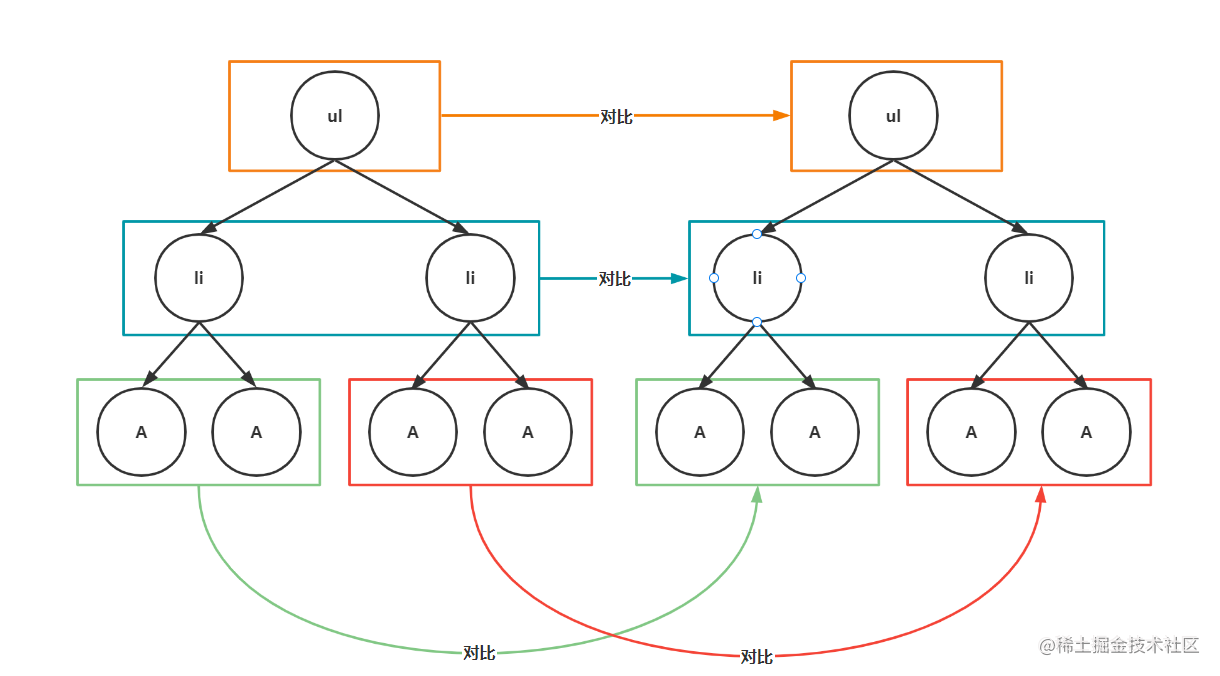
虚拟DOM
虚拟DOM就是 用普通js对象来描述DOM结构,举个例子来加深理解,如下
1
2
3
4
| <ul class="list">
<li class="item">A</li>
<li class="item">B</li>
</ul>
|
对应的虚拟dom如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| {
"tag": "ul",
"props": {"class": "list"},
"type": 1,
"children": [
{
"tag": "li",
"props": {"class": "item"},
"type": 1,
"children": [
{
"value": "A",
"type": 3,
"children": []
}
]
},
{
"tag": "li",
"props": {"class": "item"},
"type": 1,
"children": [
{
"value": "B",
"type": 3,
"children": []
}
]
},
]
}
|
- 虚拟DOM中,在DOM的状态发生变化时,新旧的虚拟DOM会进行Diff运算比较,来更新只需要被替换的DOM,而不是全部重绘。
patch
就是对比新旧的虚拟节点
- 如果当前层节点一致,则对比下一层(深层对比)
- 否则就直接创建新的虚拟节点,插入在旧虚拟节点的之前,并删除旧虚拟节点
核心代码
1
2
3
4
5
6
7
8
9
10
11
| if (sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode,vnode)
} else {
var oldElm = oldVnode.elm
var parentElm = nodeOps.parentNode(oldElm)
createElm(vnode,null,parentElm,nodeOps.nextSibling(oldElm))
if (isDef(parentElm)) { removeVnodes([oldVnode], 0, 0) }
}
|
patchVnode
这个方法的入参是 新旧虚拟节点,若新旧节点相等直接return;否则会判断新Vnode是否是文本节点
新Vnode是文本节点:
替换文本内容
新Vnode不是文本节点则会再进行如下判断
- 新旧vnode有子节点:子节点不相等则进行子节点对比更新变化的地方
- 新vnode有子节点:将新vnode的子节点插入
- 旧vnode有子节点:移除旧vnode的子节点
- 旧vnode是文本节点:置空文本内容
如下是patchVnode函数的核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| var oldCh = oldVnode.children
var ch = vnode.children
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) {
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
}
}
else if (isDef(ch)) {
if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
}
else if (isDef(oldCh)) {
removeVnodes(oldCh, 0, oldCh.length - 1)
}
else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
}
else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text)
}
|
updateChildren
这是diff算法里比较重要的方法,主要就是进行子节点的对比,通过新的子节点集合和旧的子节点集合的 首尾指针 交叉对比,如下图
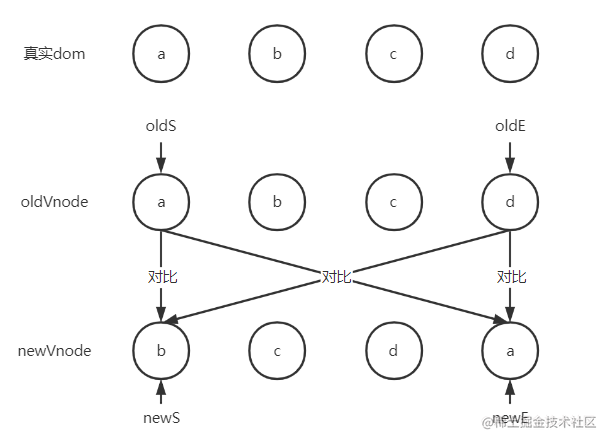
下面是updateChildren的主要代码(代码看不懂的可先跳过代码,去看例子解析并和代码一起理解)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
}
else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
}
else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnod)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
insertBefore(parentElm,oldStartVnode.elm,nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode)
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}
else {
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
createElm(newStartVnode, null, parentElm, oldStartVnode.elm)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode()
oldCh[idxInOld] = undefined
nodeOps.insertBefore(parentElm,vnodeToMove.elm,oldStartVnode.elm)
}
else {
createElm(newStartVnode, null, parentElm, oldStartVnode.elm)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx);
}
else if (newStartIdx > newEndIdx) {
removeVnodes(oldCh, oldStartIdx, oldEndIdx)
}
|
例子
下面通过一个例子来模拟updateChildren方法
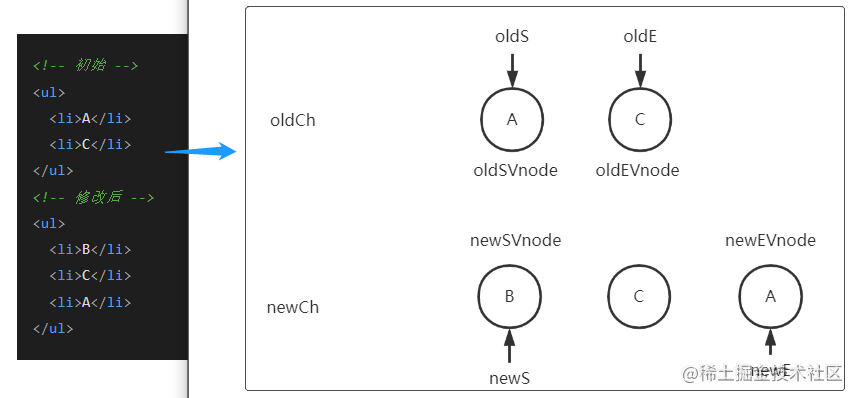
通过节点首尾指针交叉对比得知,oldSVnode = newEVnode,所以将oldSVnode移动到oldEVnode后面,指针向内移动(如图下)
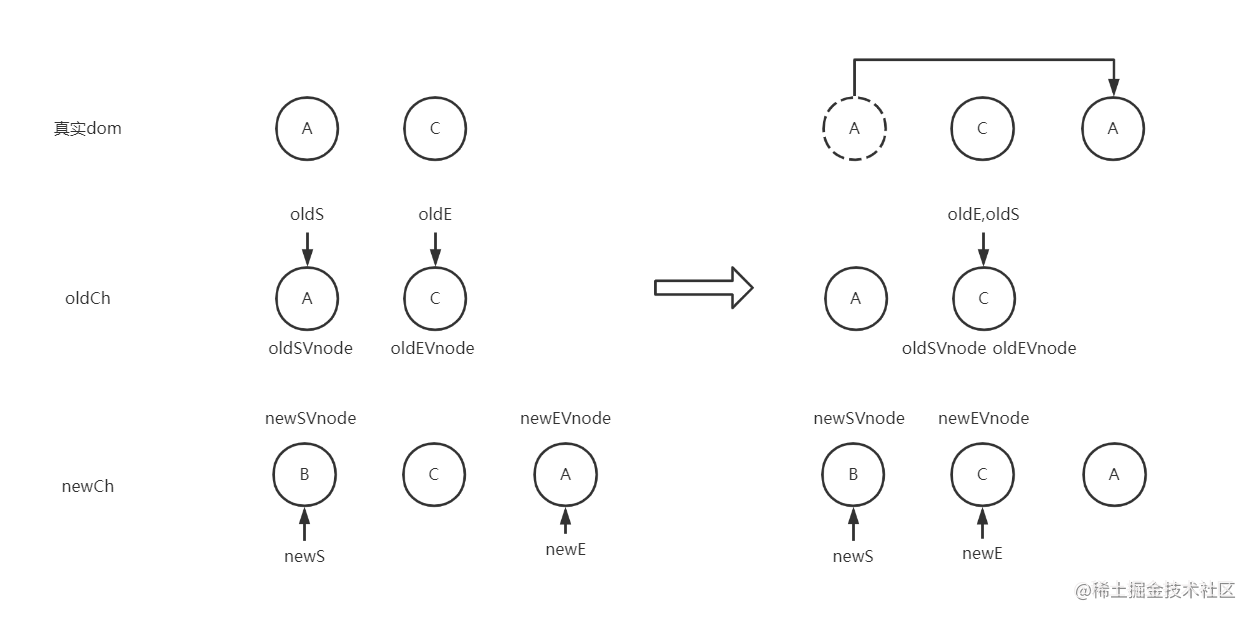
继续对比,oldEVnode = newEVnode,dom不变,oldE,newE向左移动(如图下)
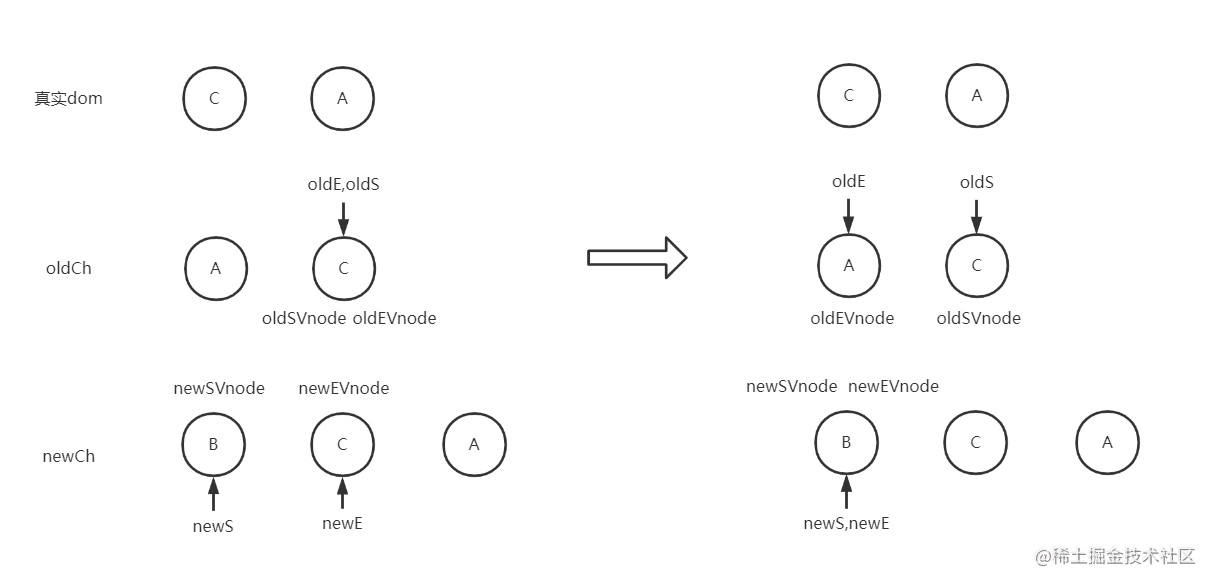
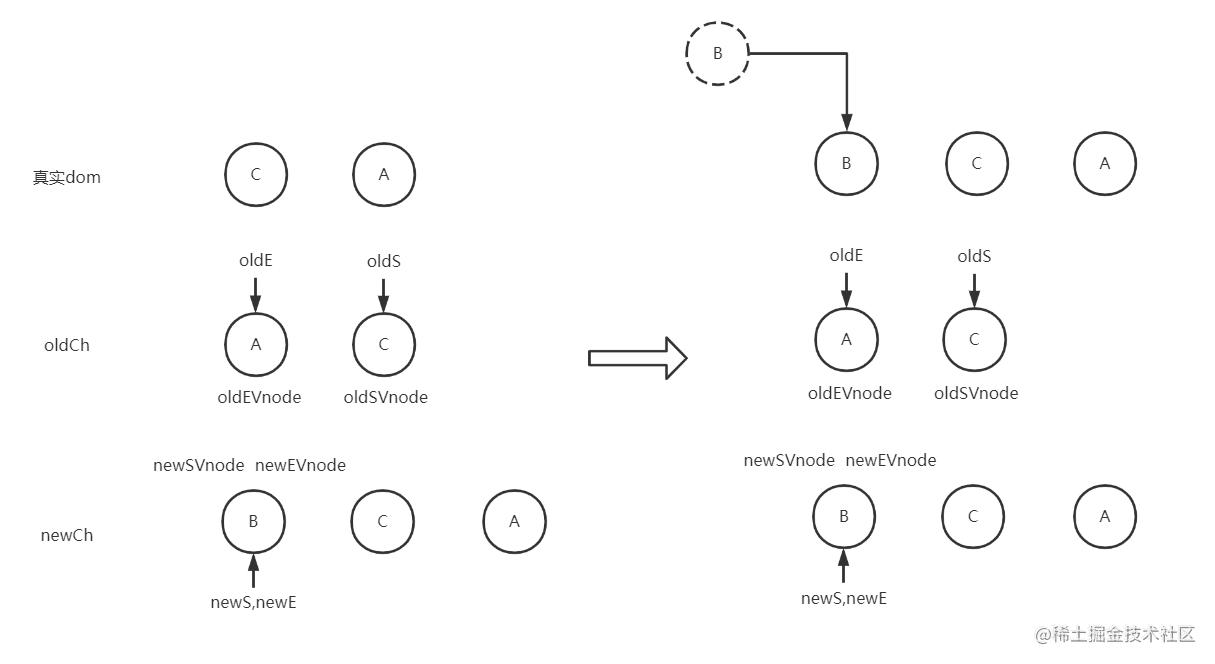
这个时候oldS > oldE,跳出while循环,往节点C前面插入newS-newE指针之间的节点(即B节点)(如图下)
v-for加key的作用
v-for默认使用就地复用策略,根据上面的代码,当节点有 key 的时候会复用 key 相同并且一致的节点。
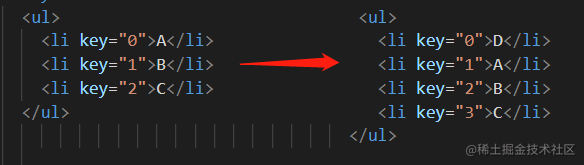
还有一个经常遇到的问题,为什么不能用index当作key? 我们来根据代码一起分析一下。
假设场景如下
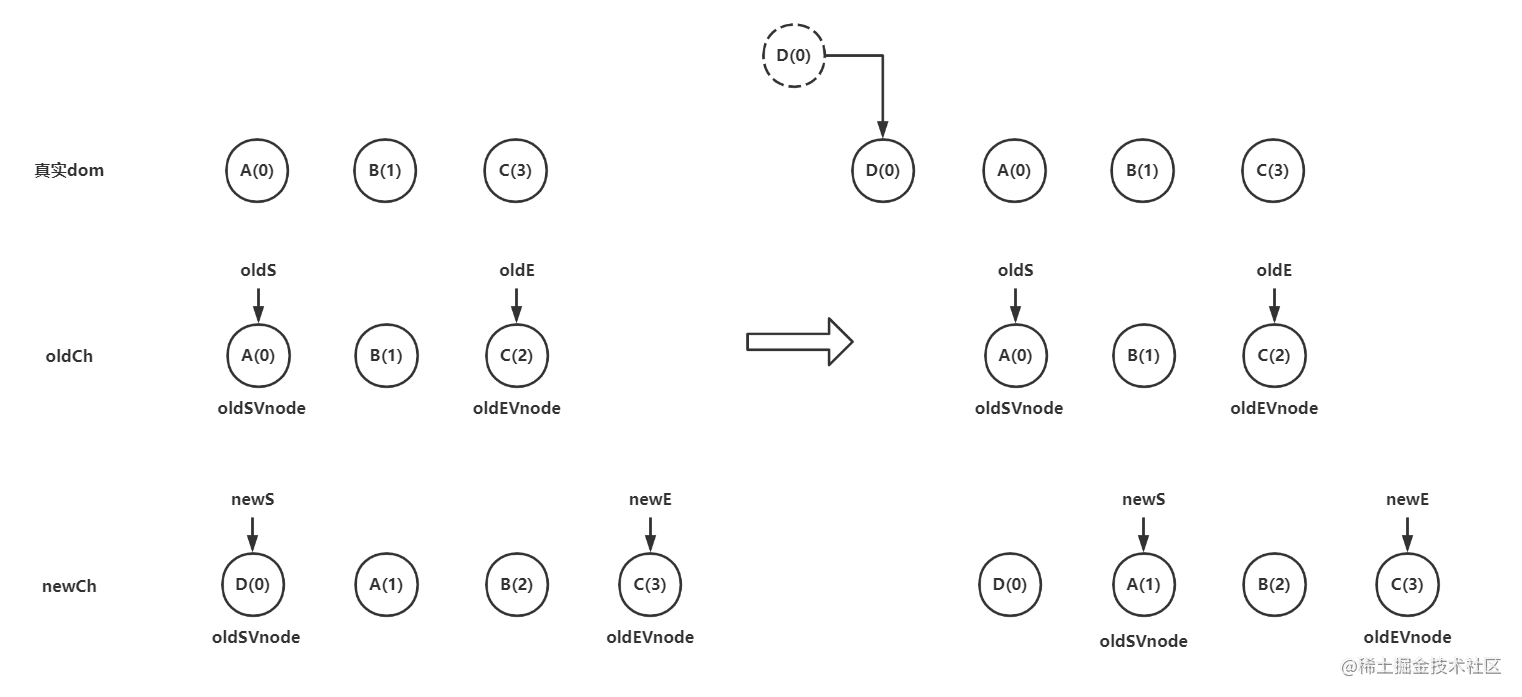
当我们往遍历的data里的头部添加一个D时,我们在子节点对比的时候,因为sameVnode方法是有对比两个节点的key,所以在新旧节点首尾节点对比时都不相同。只能进入else的判断逻辑,下面代码只展示当前例子进入的else判断逻辑代码请结合上图理解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
else {
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = {
'0': 0,
'1': 1,
'2': 2,
}
}
idxInOld = 0
createElm(newStartVnode, null, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}
}
|
以此类推最终会往真实dom里的 A 节点插入新建 D(0),A(1),B(2),C(3) 节点,直到newS>newE,批量删除(A(0),B(1),C(2))。
总结: 当我们用index做key的时候,添加一个节点,就导致了所有节点被替换,当节点数量多的时候,就会严重影响性能。如果用唯一的字段值当key的话,就可以直接复用起来。所以一般建议用唯一的字段值当作key。
vue3与vue2的Diff算法的优化点
在Vue2.0当中,当数据发生变化,它就会新生成一个新的虚拟DOM树,并和之前的旧的虚拟DOM树进行比较,找到不同的节点然后更新。但这比较的过程是 全量 的比较,也就是每个节点都会彼此比较。但其中很显然的是,有些节点中的内容是不会发生改变的,那我们对其进行比较就肯定消耗了时间。
所以在Vue3.0当中,就对这部分内容进行了优化:在创建虚拟DOM树的时候,会根据DOM中的内容会不会发生变化,添加一个静态标记。那么之后在与上次虚拟节点进行对比的时候,就只会对比这些带有静态标记的节点。
静态提升
- vue2不管是否参与更新,都会重新创建再渲染。
- vue3对于不参与更新的元素,会做静态提升,只被创建一次,在渲染时直接复用即可。
最长递增子序列
vue3中在子节点对比的时候对 于乱序并且有可复用的节点 的情况会采用最长递增子序列来减少对dom的移动操作。
简单介绍一下什么是最长递增子序列
- 数组
[3, 6, 2, 7] 是数组 [0, 3, 1, 6, 2, 2, 7] 的最长递增子序列。
- 数组
[2, 3, 7, 101] 是数组 [10 , 9, 2, 5, 3, 7, 101, 18]的最长递增子序列。
- 数组
[0, 1, 2, 3] 是数组 [0, 1, 0, 3, 2, 3]的最长递增子序列。
在vue3的diff算法中进移动可复用节点的时候时候会用到最长递增子序列,下面举个例子
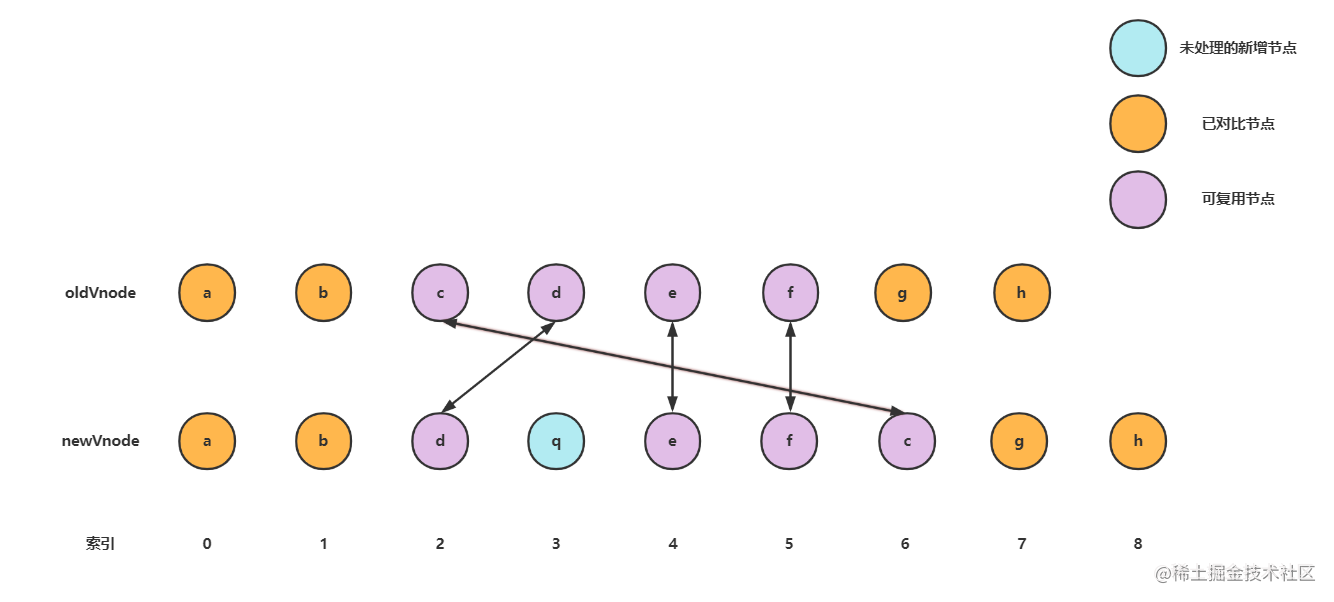
vue3中会通过一个变量newIndexToOldIndexMap(存储可复用节点的索引)来映射 新的子序列中的节点下标 对应于 旧的子序列中的节点的下标。(源码中newIndexToOldIndexMap[newIndex - s2] = i + 1 加1是为了避免 i 为 0 的特殊情况,影响对后续最长递增子序列的求解)
例如当前例子的newIndexToOldIndexMap = [3, 0, 4, 2, 5]
解释:3的意思就是newVnode的d节点对应可复用oldVnode的d节点的下标索引为3。
newIndexToOldIndexMap的最长递增子序列为[3, 4, 5]其对应的索引为[0, 2, 4]
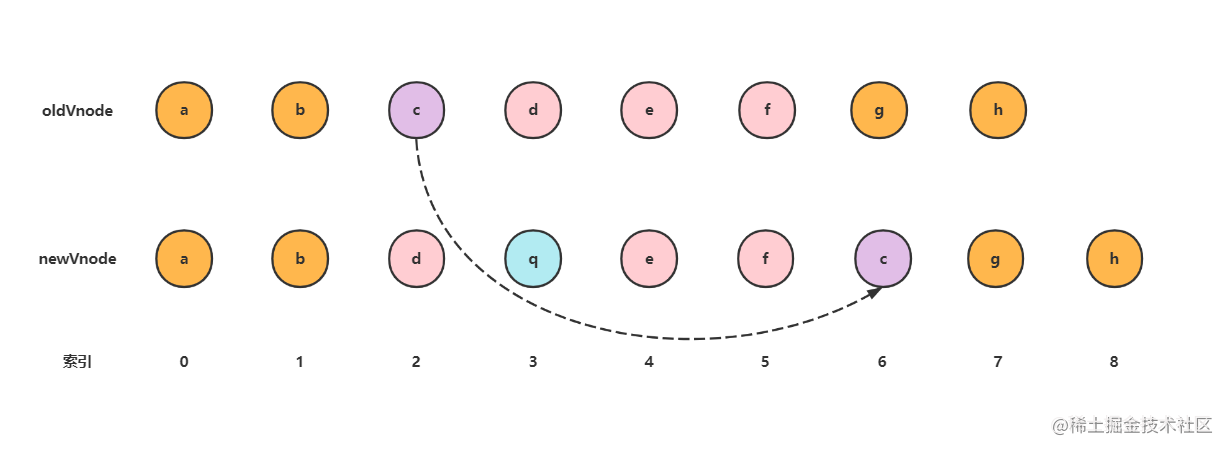
我们得出最长递增子序列对应的索引后,就可以知道哪些节点在变化前后 相对位置 没有发生变化,哪些节点需要进行移动。如上图,d,e,f节点的相对位置是没有变化的,我们只需要移动c节点,和创建q节点。
最长递增子序列可以让我们通过最小变动实现节点复用,递增的节点是不变的,我们只需要去操作非递增的节点。







